クラスタリング
数値データを階層的クラスタリングし、デンドログラムで構造を可視化できます。
クラスタ数の自動最適化と、特徴量重要度の表示にも対応しています。
操作デモ動画
以下の動画で、操作方法をご確認いただけます。
操作方法
処理タイプ>分析タイプ>クラスタリング を選択します。

基本設定
注記
以下の説明では、サンプルデータ「ワイン」を使用しています。
-
クラスタリングする変数 を選択します。数値列から複数選択できます。
-
クラスタリング手法 を選択します。
 クラスタリング手法の概要
クラスタリング手法の概要- ward:クラスタ内のばらつき(分散)の増加が最小になる組み合わせを優先します。球状で均一なクラスタを作りやすい手法です。
- complete:クラスタ間の「最も遠い点同士」の距離で判定します。クラスタ同士を明確に分けたいときに向きます。
- average:クラスタ間の全点ペアの平均距離で判定します。極端な外れ値の影響を受けにくく、バランス型です。
- weighted:各クラスタを同じ重みとして平均距離を計算します。クラスタサイズの偏りが大きい場合に大クラスタへの偏りを抑えます。
- centroid:クラスタの重心(平均ベクトル)間の距離で判定します。重心位置の変化を重視したい場合に使います。
- median:クラスタ代表点(中央値ベース)間の距離で判定します。代表値ベースで安定した結合を行いたいときに使います。
-
解析 をクリックして実行します。

オプション設定
- クラスタサイズ を指定します。
- クラスタ数を自動最適化 を有効にすると、自動最適化の設定が優先されます。
結果の見方
デンドログラムと特徴量重要度が表示されます。
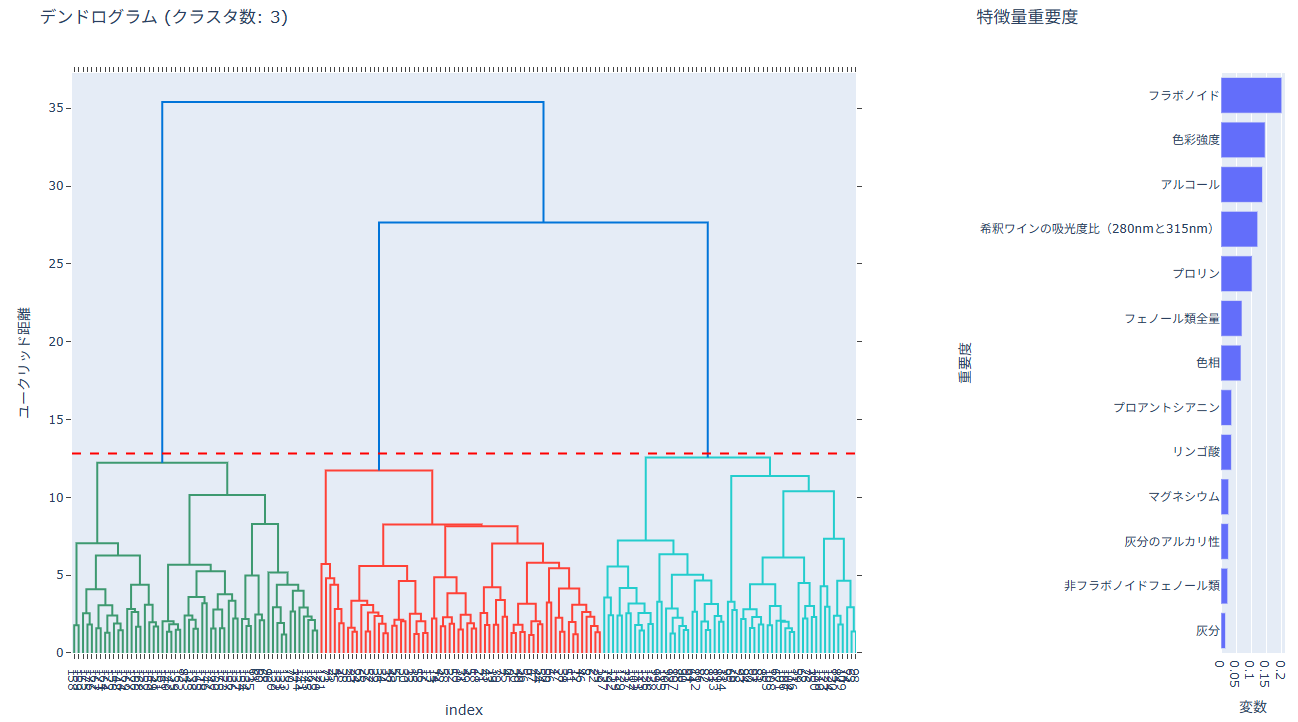
デンドログラム
- 枝の高さが距離(非類似度)を示します。
- 赤い破線がクラスタの分割位置です。
特徴量重要度
- ランダムフォレストで算出した重要度を表示します。
- 値が大きい変数ほど、クラスタ分割に影響が大きいと解釈できます。
注意点
- 使用する列は数値列に限定してください。
- 欠損値が含まれる場合は解析できません。事前に欠損の除外や補完を行ってください。
- 自動最適化を有効にすると、クラスタサイズの指定より自動最適化の設定が優先されます。