機械学習(分類)
分類モデルの構築・感度分析を実施できます。 目的変数に対する説明変数の影響の把握も可能です。
操作デモ動画
以下の動画で、操作方法をご確認いただけます。
操作方法
処理タイプ>分析タイプ>機械学習(分類) を選択します。

モデル構築
注記
以下の説明では、サンプルデータ「ワイン」を使用しています。
「品種」は事前に型変換でObject型に変換しています。
説明変数(入力値)と目的変数(出力値)の関係 を表すモデルを作成します。
-
モデル構築 モードを選択します。

-
目的変数 と 説明変数 を選択します。

-
モデルタイプ を選択します。
 モデルタイプ一覧
モデルタイプ一覧以下の手法が選択可能です。
- ロジスティック回帰
- ランダムフォレスト
- LightGBM
ハイパーパラメータの設定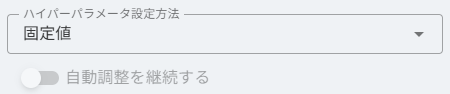
ハイパーパラメータは 固定 または 自動調整 から選択できます。自動調整では1回の実行につき10回の試行を行います。前回のチューニング結果が存在する場合、そこから継続することも可能です。
-
モデル構築 を実行します。

-
モデルが作成されました。
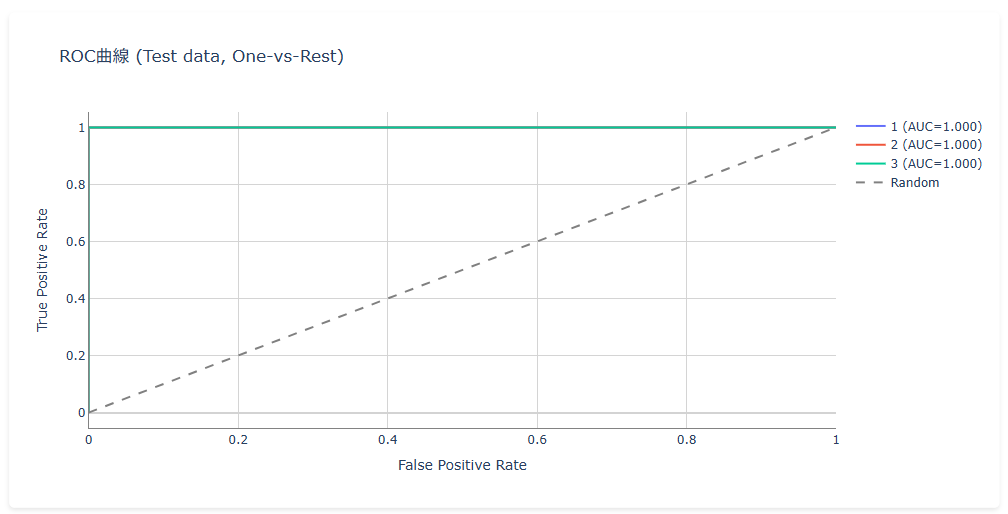
モデルの評価指標 と 混同行列、ROC曲線 が表示されます。
多クラス分類の場合、ROC曲線はOne vs Rest方式で各クラス分が表示されます。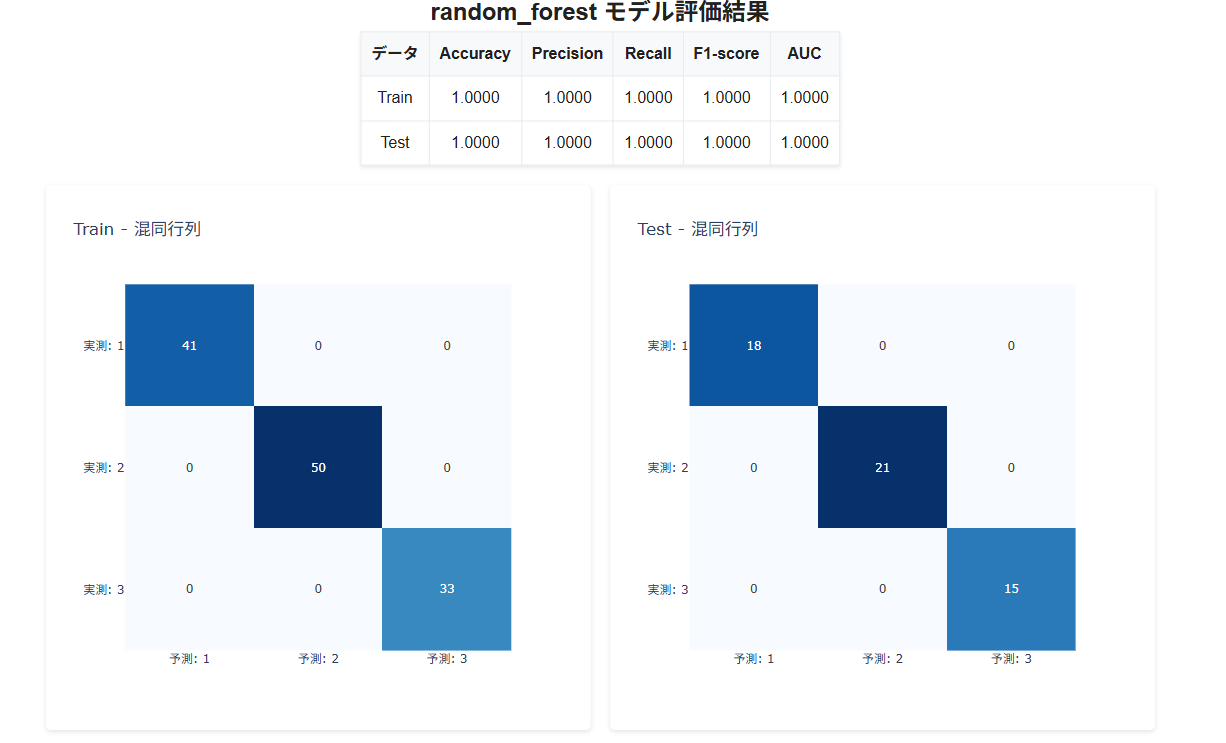
 モデルの評価指標
モデルの評価指標- Accuracy:正解率。全データのうち正しく分類できた割合。
- Precision:適合率。陽性と予測したデータのうち実際に陽性だった割合。
- Recall:再現率。実際に陽性のデータのうち陽性と予測できた割合。
- F1スコア:PrecisionとRecallの調和平均。
- AUC:ROC曲線下の面積。1に近いほど精度が高い。多クラス分類の場合はOne vs Rest方式でクラスごとに算出されます。
目的変数に対する説明変数の影響 も確認できます。
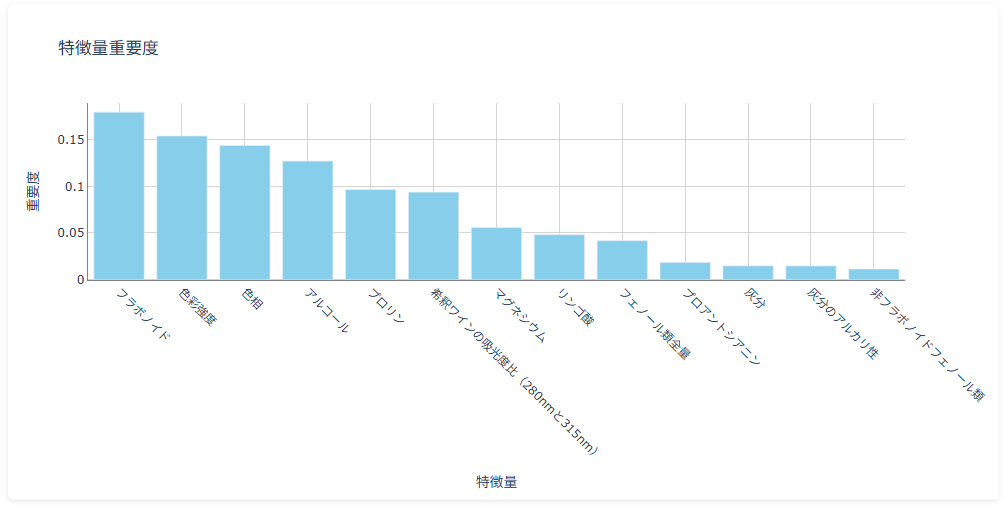
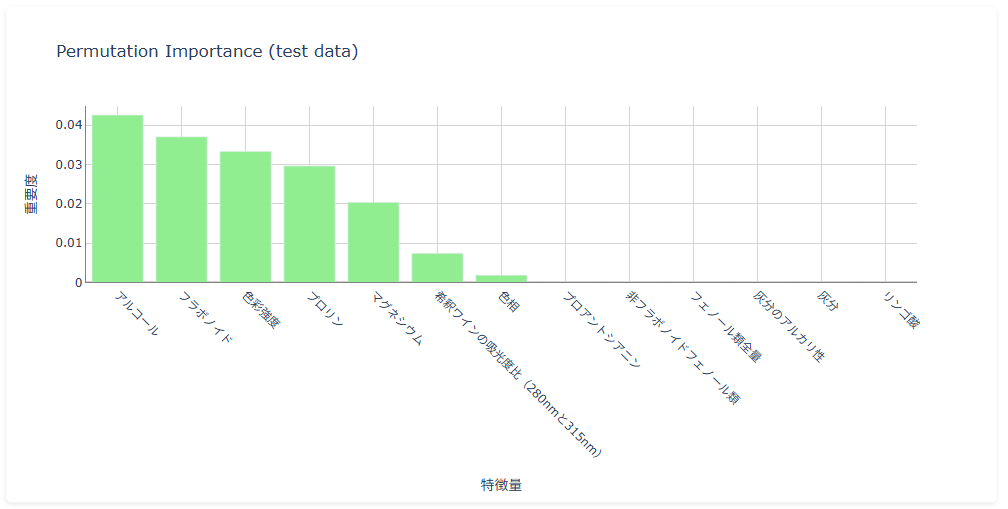 モデル解釈の指標
モデル解釈の指標- 特徴量重要度 :モデルが学習する際にどの説明変数を重視したかを示す指標。正の値を取り、値が大きいほど影響が大きい。
- Permutation Importance :モデルの予測精度にどの説明変数が貢献しているかを示す指標。基本的に正の値を取り、値が大きいほど影響が大きい。
-
作成したモデルはモデルアイコンをクリックして保存できます。
 モデルのダウンロード
モデルのダウンロード保存したモデルはダウンロードすることができます。
感度分析
注記
感度分析にはモデルの保存が必要です。
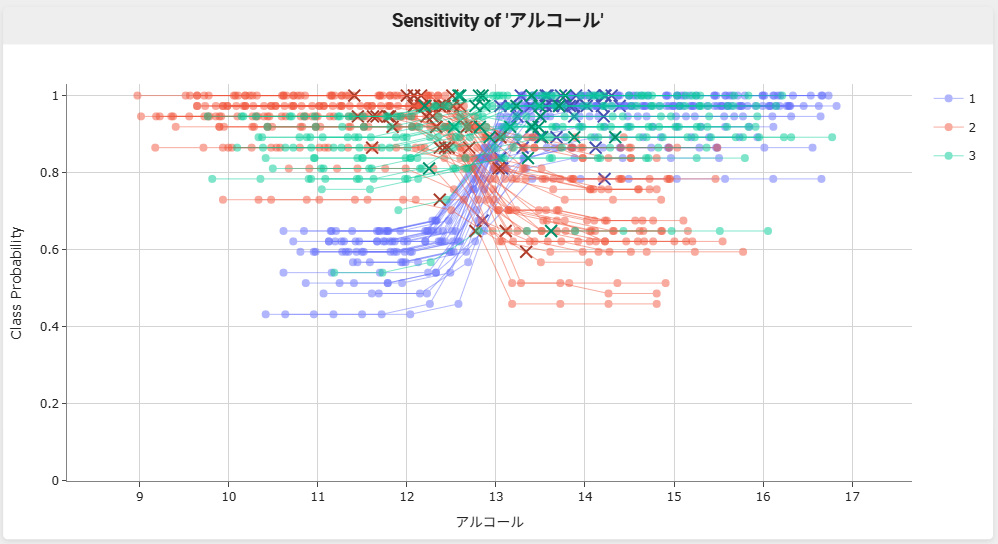
作成したモデルに対して、説明変数の値を変えた時に目的クラスの確率がどう変わるか を調べます。
-
感度分析 モードを選択します。

-
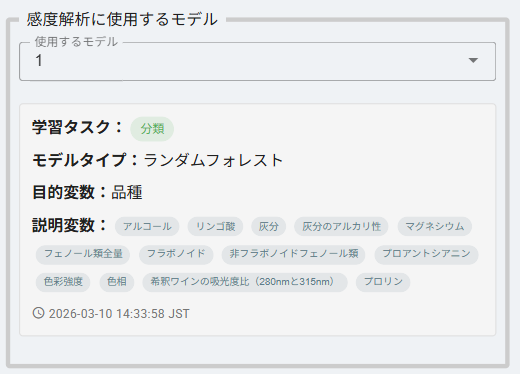
使用するモデルを選択します。
-
分析する変数を選択します。

-
感度分析を実行します。

-
分析結果が表示されます。
説明変数の値を変化させたときに、各クラスに分類される確率がどう変化するかを確認できます。