線形回帰
目的変数を説明変数で予測する回帰モデルを作成できます。
単回帰・重回帰(最小二乗法)・正則化回帰・PLS・ステップワイズ法に対応しています。
操作デモ動画
以下の動画で、操作方法をご確認いただけます。
操作方法
処理タイプ>分析タイプ>線形回帰 を選択します。

基本設定
注記
以下の説明では、サンプルデータ「医薬品の有効成分」を使用しています。
-
モード を選択します。
 モード一覧
モード一覧以下のモードが選択可能です。
- 単回帰
- 重回帰(最小二乗法)
- 重回帰(正則化手法)
- PLS
- ステップワイズ法
-
目的変数 を選択します。数値列から選択します。

-
説明変数 を選択します。数値列から複数選択できます。

-
解析 をクリックして実行します。

単回帰の結果とその解釈
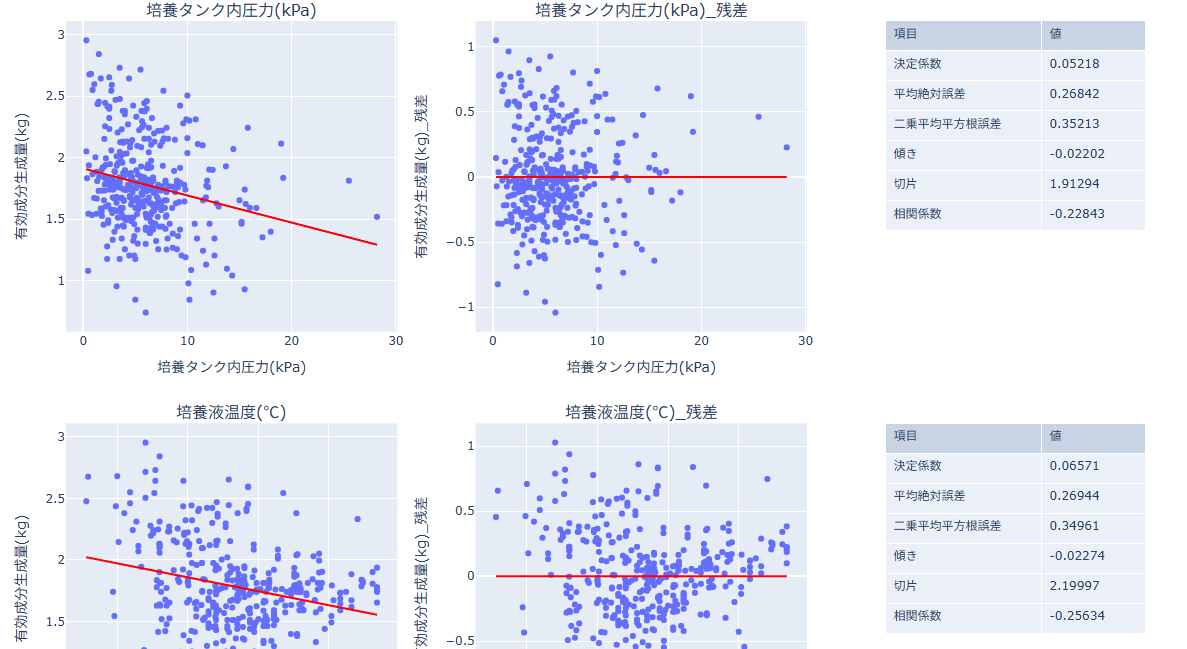
単回帰の結果の見方
- 回帰プロット(左):説明変数(X軸)と目的変数(Y軸)の散布図に回帰直線を重ねて表示します。直線とのずれから当てはまりを確認します。
- 残差プロット(中):残差の偏りや外れ値を確認します。0線の周りにランダムに散らばっているかを見ます。
- 回帰サマリー(右):決定係数、平均絶対誤差、二乗平均平方根誤差、傾き、切片、相関係数を確認します。
- 決定係数:モデルが目的変数のばらつきをどれだけ説明できているかを示します(1に近いほど当てはまりが良い)。
- 平均絶対誤差:予測値と実測値の差の絶対値の平均です(小さいほど良い)。
- 二乗平均平方根誤差:誤差を二乗して平均し平方根を取った値です(外れ値の影響を受けやすく、小さいほど良い)。
- 傾き:説明変数が1増えたときに目的変数がどれだけ変化するかを示します。
- 切片:説明変数が0のときの目的変数の推定値です。
- 相関係数:説明変数と目的変数の線形な関係の強さと方向を示します(-1〜1)。
重回帰(最小二乗法)の結果とその解釈
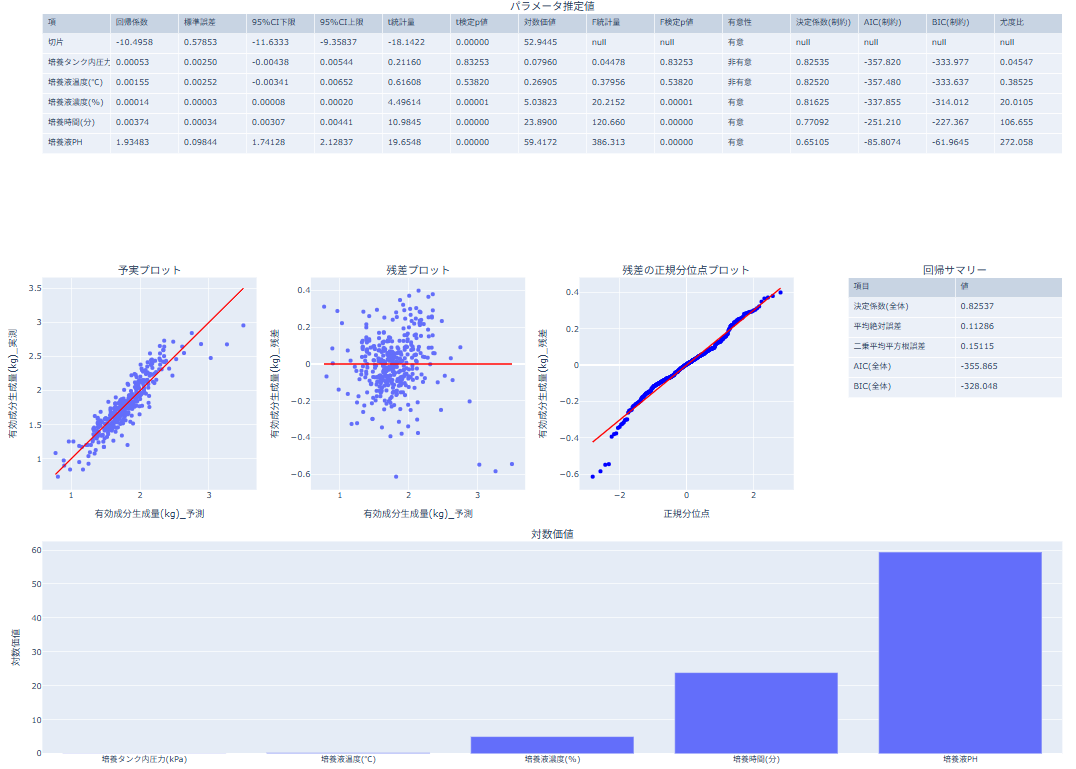
重回帰(最小二乗法)の結果の見方
- パラメータ推定値テーブル(上):各説明変数の回帰係数、標準誤差、p値、有意性などを確認します。
- 予実プロット(中1列):予測値と実測値の一致度を確認します。点が一致線に近いほど当てはまりが良いと判断します。
- 残差プロット(中2列):残差の偏りや外れ値を確認します。0線の周りにランダムに散らばっているかを見ます。
- 残差の正規分位点プロット(中3列):残差がおおむね正規分布に従うかの目安を確認します。
- 回帰サマリー(中4列):決定係数、平均絶対誤差、二乗平均平方根誤差、AIC、BIC を確認します。
- 対数価値(下):各説明変数の影響度の目安として確認します。値が大きいほど影響が大きいと判断します。
オプション設定
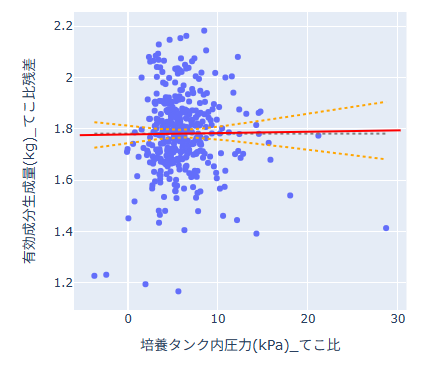
- てこ比プロットを表示する変数 を指定できます(任意)。指定した場合、下段にてこ比プロットが追加表示されます。
- てこ比プロット は、ほかの説明変数の影響を調整したうえで、指定した変数が目的変数に与える影響を可視化するプロットです。
- 赤い実線:調整後の回帰直線(その変数の効果の方向と大きさ)です。
- オレンジの点線:回帰直線の信頼区間(平均の信頼区間)です。
- 青い点:観測データ点です(点の散らばりでばらつきを確認します)。
- グレーの点線:目的変数の平均を示す基準線です。

重回帰(正則化手法)の結果とその解釈
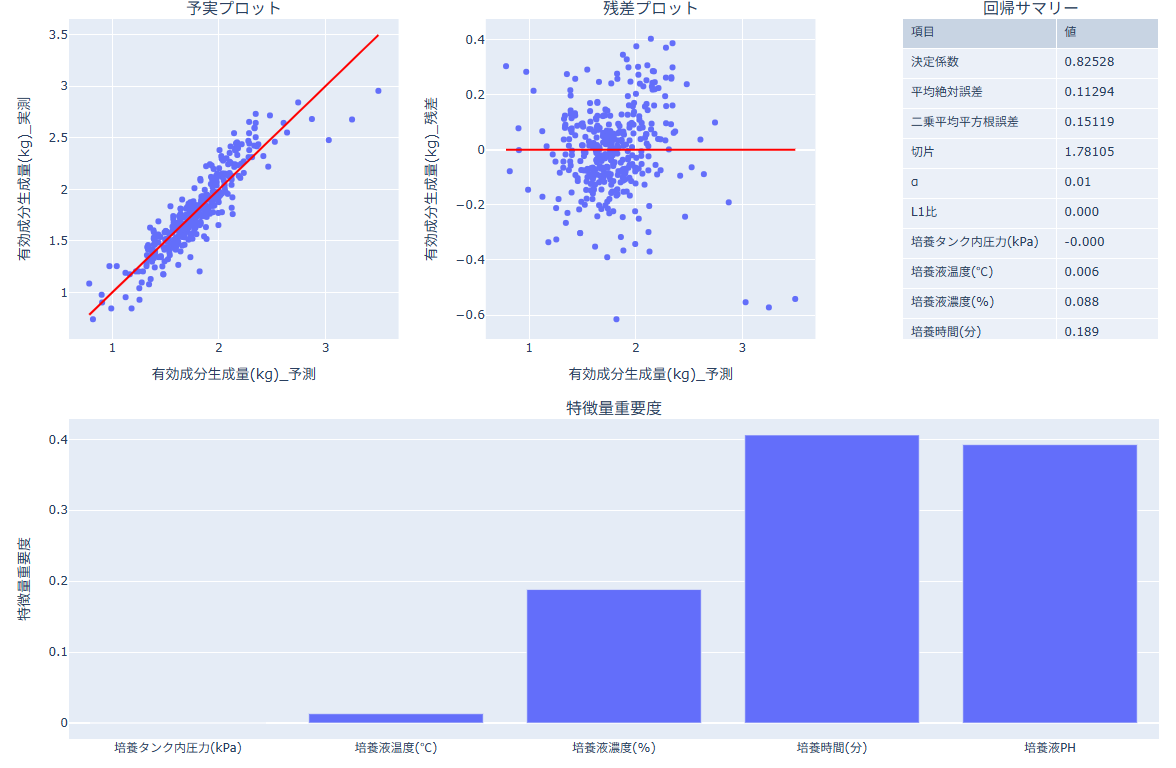
重回帰(正則化手法)の結果の見方
- 予実プロット(上左):予測値と実測値の一致度を確認します。点が一致線に近いほど当てはまりが良いと判断します。
- 残差プロット(上中):残差の偏りや外れ値を確認します。0線の周りにランダムに散らばっているかを見ます。
- 回帰サマリー(上右):決定係数、平均絶対誤差、二乗平均平方根誤差、切片、α、L1比、各説明変数の係数を確認します。
- 決定係数:モデルが目的変数のばらつきをどれだけ説明できているかを示します(1に近いほど当てはまりが良い)。
- 平均絶対誤差:予測値と実測値の差の絶対値の平均です(小さいほど良い)。
- 二乗平均平方根誤差:誤差を二乗して平均し平方根を取った値です(外れ値の影響を受けやすく、小さいほど良い)。
- 切片:説明変数がすべて0のときの目的変数の推定値です。
- α:正則化の強さです。大きいほど係数を強く縮小します。
- L1比:L1とL2の混合比です(0に近いとL2寄り、1に近いとL1寄り)。
- 特徴量重要度(下):係数の大きさを正規化した指標です。絶対値が大きいほど寄与が大きいと判断します。
オプション設定
- 説明変数のスケーリング(標準化 / 正規化)を必要に応じて指定します。
- 正則化項の追加(L1 / L2 / ElasticNet)を選択します。

PLSの結果とその解釈
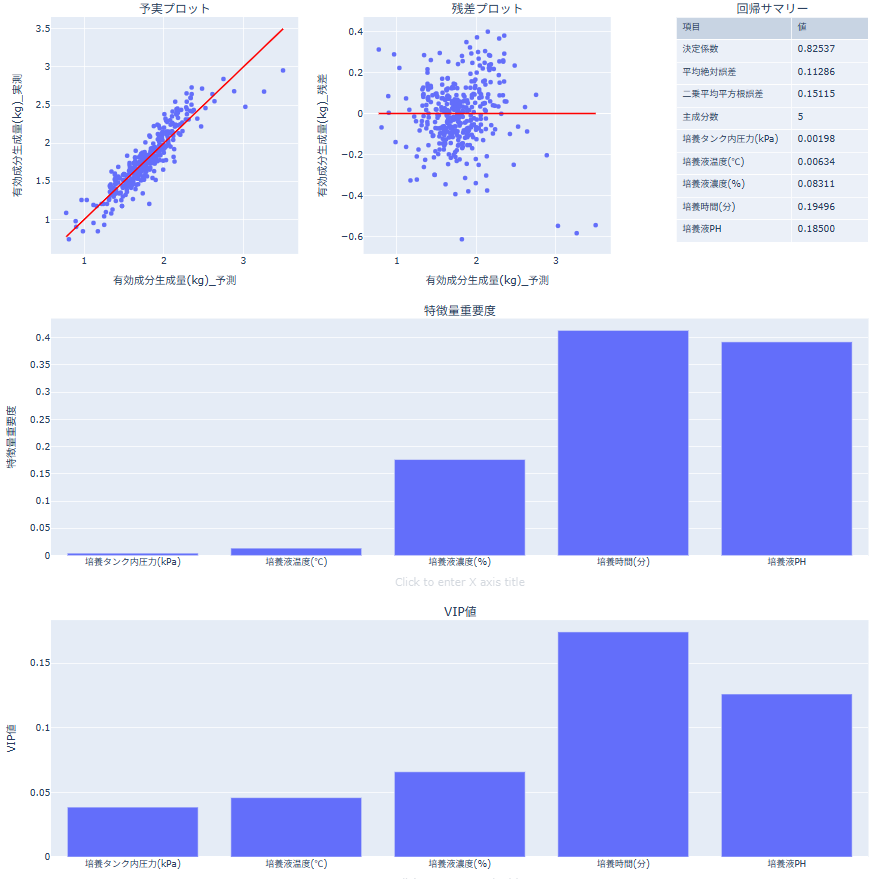
PLSの結果の見方
- 予実プロット(上左):予測値と実測値の一致度を確認します。点が一致線に近いほど当てはまりが良いと判断します。
- 残差プロット(上中):残差の偏りや外れ値を確認します。0線の周りにランダムに散らばっているかを見ます。
- 回帰サマリー(上右):決定係数、平均絶対誤差、二乗平均平方根誤差、主成分数、各説明変数の係数を確認します。
- 決定係数:モデルが目的変数のばらつきをどれだけ説明できているかを示します(1に近いほど当てはまりが良い)。
- 平均絶対誤差:予測値と実測値の差の絶対値の平均です(小さいほど良い)。
- 二乗平均平方根誤差:誤差を二乗して平均し平方根を取った値です(外れ値の影響を受けやすく、小さいほど良い)。
- 主成分数:モデルで使用した潜在変数(成分)の数です。
- 各説明変数の係数:各変数が予測に与える方向(正/負)と強さを示します。
- 特徴量重要度(中):係数の大きさを正規化した指標です。絶対値が大きいほど寄与が大きいと判断します。
- VIP値(下):PLSにおける変数重要度指標です。各変数が全主成分を通じて予測にどれだけ寄与したかを表します。
- 一般的な目安として、1以上は重要、0.8〜1.0は境界、0.8未満は寄与が小さいと解釈します。
- VIP値は影響の大きさ(絶対的な寄与)の参考指標です。影響の方向(正/負)は係数テーブルで確認します。
オプション設定
- 主成分の数 を指定します。

ステップワイズ法の結果とその解釈
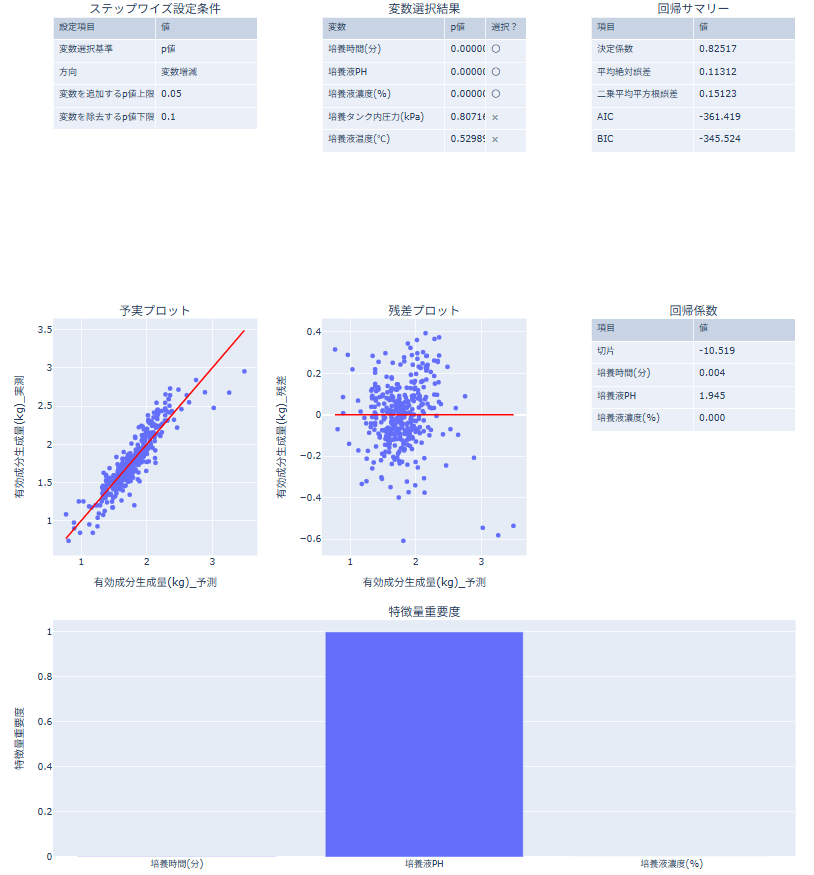
ステップワイズ法の結果の見方
- ステップワイズ設定条件(上左):変数選択基準、方向(増減/増加/減少)、追加・除外のp値しきい値を確認します。
- 変数選択結果(上中):各変数の指標値(p値またはAIC/BIC)と、採用/非採用(○/×)を確認します。
- 回帰サマリー(上右):決定係数、平均絶対誤差、二乗平均平方根誤差、AIC、BIC を確認します。
- 予実プロット(中左):予測値と実測値の一致度を確認します。点が一致線に近いほど当てはまりが良いと判断します。
- 残差プロット(中中):残差の偏りや外れ値を確認します。0線の周りにランダムに散らばっているかを見ます。
- 回帰係数テーブル(中右):切片と、選択された説明変数の係数を確認します。
- 特徴量重要度(下):選択された変数ごとの影響度を比較します。絶対値が大きいほど寄与が大きいと判断します。
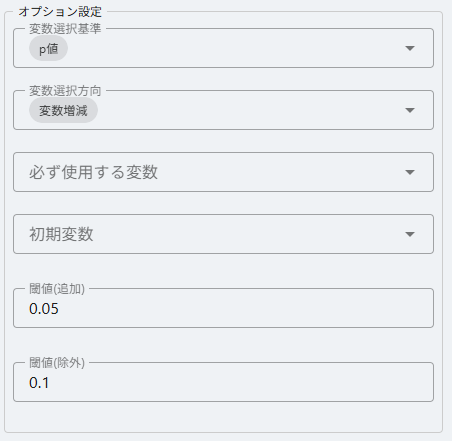
オプション設定
- 変数選択基準(p値 / AIC / BIC)を選択します。
- 変数選択方向(増減 / 増加 / 減少)を選択します。
- 必ず使用する変数 を設定できます。
- 初期変数 は「変数増減」時のみ指定できます。
- 閾値(追加/除外) は基準がp値のときのみ使用します。
注意点
- 目的変数・説明変数は数値列を使用してください。
- 欠損値が含まれる場合は解析できません。事前に欠損の除外や補完を行ってください。
- 説明変数に目的変数と同じ列が含まれると自動的に除外されます。